
软件介绍/功能
 Text-R官方版是一款功能实用的OCR文本识别软件,Text-R官方版可以识别PDF文件和图像中的文本,立即将其转换为任何用户级别的可编辑文档。文本可以保存在新的可编辑PDF或RTF文档(Word)中。格式保持接近原始格式,因此在大多数情况下,不需要后期处理。
Text-R官方版是一款功能实用的OCR文本识别软件,Text-R官方版可以识别PDF文件和图像中的文本,立即将其转换为任何用户级别的可编辑文档。文本可以保存在新的可编辑PDF或RTF文档(Word)中。格式保持接近原始格式,因此在大多数情况下,不需要后期处理。
软件简介
Text-R官方版能够用于识别PDF文档中的文本和识别图像文件中的文本!从扫描的纸质文档制成的PDF文件和图像包含无法复制或编辑的文本。 但是,由于文档数量大,以及相关的高时间花费,省去了手动重新键入内容。该软件还可以识别PDF文件和图片中的文本,即使对于外行也是如此。 文本可以保存在新的可编辑PDF或RTF文档(Word)中。 格式保持接近原始格式,因此在大多数情况下,不需要后处理。集成的词典和专业的OCR过滤器可确保文本识别的高精度。 因此,也可以识别偏斜的文本和旋转的文档。
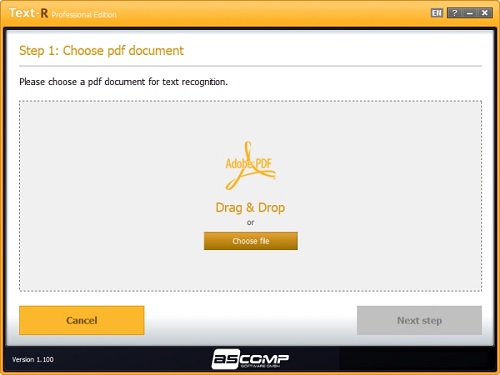
使用方法
一、检测PDF文档中的文本
如果要识别和提取PDF文档中的文本,请单击“检测PDF文档中的文本”按钮。
步骤1:选择PDF文件
有两种选择PDF文档进行文本识别的选项:
1、拖放
通过在Windows资源管理器中单击鼠标左键并按住不放,然后将其拖到Text-R窗口中,将PDF文档从Windows资源管理器中拖到Text-R的灰色拖放区域中。
如果操作成功,则将PDF文档加载并显示在Text-R中。
2、选择文件
使用Windows已知的“文件打开”对话框来手动选择PDF文档。 选择所需的文档,然后单击“打开”。
如果要从Text-R删除加载的PDF文档,请单击“重置”。
二、检测图像文件中的文本
如果要从图像文件中识别和提取文本,请单击“在图像文件中检测文本”按钮。
步骤1:选择图片文件
选择图片文件进行文本识别有两个选项:
1、拖放
通过在Windows资源管理器中单击鼠标左键并按住不放并将其拖到Text-R窗口中,将图像文件从Windows资源管理器拖到Text-R的灰色拖放区域中。
如果操作成功,则将图像文件加载并显示在Text-R中。
2、选择文件
使用Windows打开文件对话框手动选择图像文件。 选择所需的文件,然后单击“打开”。
回报
如果要从Text-R删除加载的图像文件,请单击“重置”。
三、定义设置
在第二步中,指定用于文本识别的设置。
OCR选项
Text-R提供了各种OCR选项,以增加和提高文本识别的识别率。
扫描条码
如果要读取条形码的内容(文本和链接)并以纯文本显示,请激活“扫描条形码”按钮。
识别/校正歪斜图像
如果Text-R还应该检测并纠正歪斜的文本段落(例如由于扫描不准确),则激活“检测/纠正歪斜的图像”复选框。
识别旋转(90°/ 180°/ 270°)
如果Text-R应该识别旋转的文档并且应阅读其内容,请选中旋转(90°/ 180°/ 270°)。
使用干涉滤光片
如果Text-R应该优化脏的扫描文档和图像并读取其内容,请激活选项“应用噪声过滤器”。
检测/删除线
激活“检测/删除行”选项以检测和删除行。
注意:建议您在保存后手动添加行。
正确的混合字符
如果您希望Text-R删除/更正扫描单词中发现的数字,请选中“更正混合字符”选项。同样,将删除找到的数字中包含的字母/字符,这不符合数字格式。
使用字典
如果要检查词典中是否存在已识别的单词,请激活“使用词典”选项,并在必要时进行更正。
文字语言
为了使识别过程尽可能准确,您应该指定源文档的文本语言。 例如,Text-R可以使用集成到所选语言中的词典来检查已识别单词在词典中是否存在。
四、文字识别
在第三步中,检查源文档,并在未格式化的预览中显示已识别的文本。
源
在“源”区域中,可能会显示源文件的经过OCR优化的变体。缩小和放大图标允许调整源的大小。
如果文档由多页组成,则可以通过页面选择元素选择要显示的页面。
预览(未格式化)
预览显示源文档所选页面的识别文本。您可以比较源和预览,如果对文本识别的结果不满意,则可以根据需要更正上一页的CRC选项。
注意:预览未格式化,仅显示可识别的文本。它仅用于测试不同的OCR条件。
保存文件
要将检测到的文本保存在新文档中,请单击“保存文档”按钮。
目标文档可以保存为PDF,PDF / A,RTF,TXT和XML格式。我们建议保存为PDF格式,因为文本的格式和位置应尽可能与原始文档的格式和位置相对应。
历史版本
- Text-R1.00 正式版 简体中文 win7或更高版本 2020-05-11
相关软件
-

极光PDF转换器
PDF文件批量相互转换
87575 8 11-15
-

金舟PDF编辑器
PDF编辑修改删除批注
60258 51 11-25
-

福昕PDF高级编辑器
PDF文档创建和管理工具
58723 0 01-17
-

转易侠扫描王
快速识别,准确率高!
45842 0 01-19
-

闪电PDF转换器
转换功能灵活多样
35129 34 11-25
-

PDF转换成Word转换器
轻松转换,方便编辑
25130 0 01-10
-

迅捷PDF编辑器
专业PDF编辑工具
18836 15 01-16
-

迅捷PDF转换器
高质量识别,快速转换
18595 20 01-05
-

福昕pdf编辑器
处理PDF文档首选软件
11697 0 12-16
-

傲软PDF编辑2023
专业的PDF阅读编辑工具
10196 5 12-23


